

지난 포스팅에서 해시 테이블과 관련해 궁금한 점이 생겼고, 이에 대해 간단한 용어 정리만 하려니 알아야 할 내용이 많은 것 같아 이번 포스팅에서는 이에 관해 알아보려고 합니다.
Hash
- 단방향 암호화 기법
- 해시함수를 이용해 고정된 길이의 암호화된 문자열로 변환
💡용어 정리
해시함수
: 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수
+ 매핑 전 원래 데이터의 값(key), 매핑 후 데이터의 값(hash value), 매핑하는 과정(hash)
유저가 회원가입을 하려는 상황 - 유저의 아이디와 비밀번호는 DB에 저장
입력값을 그대로 내부 DB에 저장하게 되면, 한 번 해커에게 뚫리는 순간 개인 정보가 유출될 수 있음
이를 방지하기 위해 비밀번호를 암호화해서 저장하도록 하는데 이때 해시 함수를 활용해 임의의 값으로 변환
Hash Table
해시함수를 활용해 키 값을 인덱스에 배정하고, 인덱스의 값에 데이터를 넣는 자료구조
연관배열 구조(associative array): key 1개와 value 1개가 1:1로 연관되어 있는 자료구조 - key를 이용해 value를 찾을 수 있음

key는 hash function을 통해 hash로 변경돼 value와 매핑되어 bucket에 저장됨
💡 용어 정리
키(key) : 고유한 값, 해시 함수의input
- 다양한 길이의 값 가능
- 키 값 그대로 저장되면 다양한 길이만큼의 저장소를 구성해두어야 하기 때문에 함수로 값을 바꾸어 저장해야공간 효율성O
해시함수(hash function) :key를hash로 바꿔주는 역할
-key가 일정한 길이를 가지도록 변경해 저장소를 효율적으로 사용하도록 함
- 서로 다른key가 같은hash가 되는 경우에는 해시 충돌(hash collision)이 발생
* 이 해시 충돌을 발생시키는 확률을 최대한 줄이는 함수를 만들어야 함
해시(hash) : 해시 함수의 결과물
- 저장소(bucket)에서 값과 매칭되어 저장됨
값(value) : 저장소(bucket,slot)에 최종적으로 저장되는 값으로 키와 매칭되어 저장, 삭제, 검색, 접근이 가능해야 함
Hash Table Data Structure의 단점
- 순서가 있는 배열
: 상하관계, 순서가 중요한 데이터의 경우
: 해시 테이블은 순서 상관없이 key만 가지고 해시를 찾아 저장하기 때문 - 공간 효율성 낮음
: 데이터 저장 전에 저장공간 확보 필요
: 공간이 부족하거나 아예 채워지지 않은 경우 발생 가능성 O - 해시 함수의 의존도 높음
: 평균은 O(1)이지만, 해시 함수의 연산을 고려하지 않은 결과임
: 해시 함수가 복잡하면 시간도 많이 걸리게 될 것
해시 테이블의 장점
- 키를 가지고 빠르게 값에 접근하고 조작할 수 있음
ex) 주소록 저장형태의 경우, 이름-전화번호 매칭으로 데이터 처리
Insertion(저장)
해시 테이블에 자료를 저장하기 위해 해시 함수를 사용해 key를 hash로 변경해야 함
해시 함수가 input key를 특정 수로 나눈 나머지로 변경해서 출력한다고 가정했을 때, key는 넣은 수, hash는 특정 수로 나눈 나머지라고 이해하면 된다.
미리 준비해둔 저장소 중에 맞는 hash 값을 찾아 해당 값을 저장
해시 함수로 해시를 산출하는 과정에서 서로 다른 key가 동일한 hash로 변경되는 문제 발생 가능
해시 테이블은 연관배열 구조로 1:1 매칭이 되어야 한다는 규칙이 있는데, 이를 위배한 것이므로 문제를 해결하면서 저장되어야 함 = 해시 충돌(Hash Collision)
Insertion Big-O
저장 단계 시간복잡도 : O(1)key는 고유, hash function의 결과로 나온 해시와 값을 저장소에 저장하면 되기 때문
* 해시 함수의 시간복잡도는 함께 고려하지 X
최악의 경우 O(n)이 될 수 있음
= 해시 충돌로 모든 bucket의 값들을 찾아봐야 하는 경우
Deletion(삭제)
저장되어 있는 값을 삭제할 때는 bucket에서 해당 key와 매칭되는 value를 찾아 삭제
저장소에는 hash와 value가 함께 저장되어 있으니 함께 삭제하면 됨
Deletion Big-O
삭제 단계 시간복잡도 : O(1)key는 고유, hash function의 결과로 나온 해시와 매칭되는 값 삭제하면 되기 때문
* 해시 함수의 시간복잡도 함께 고려 X
최악의 경우 O(n)이 될 수 있음
= 해시 충돌로 모든 bucket의 값들을 찾아봐야 하는 경우
Search(검색)
key로 value를 찾아내는 과정은 Deletion 과정과 비슷key로 hash를 구하고 hash로 value를 찾는다.
Search Big-O
저장 단계의 시간복잡도: O(1)key는 고유, hash function의 결과로 나온 해시와 매칭되는 값 찾으면 되기 때문
* 해시 함수의 시간복잡도 함께 고려 X
최악의 경우 O(n)이 될 수 있음
= 해시 충돌로 모든 bucket의 값들을 찾아봐야 하는 경우
Hash Collision(해시 충돌)
해시 테이블은 Insertion, Deletion, Search 과정에서 모두 평균적으로 O(1)의 시간복잡도 보유
자료구조의 효율성 측면에서 우수하다는 장점이 있음
하지만 이전 설명에서 반복적으로 등장했듯이, 해시 충돌이 발생할 수 있다는 단점이 있음hash를 이용한 자료구조 방식에서
무한한 값(key)을 유한한 값(hash)로 표현하면서 서로 다른 2개 이상의 유한한 값이 동일한 출력 값을 가지게 될 수 있음

위의 그림을 예시로 들어 이해해보자.
John과 Sandra의 hash가 같은 상황 = hash collision
1:1 규칙이 지켜지지 않았음!
충돌 해결방법
1. Chaining(체이닝)
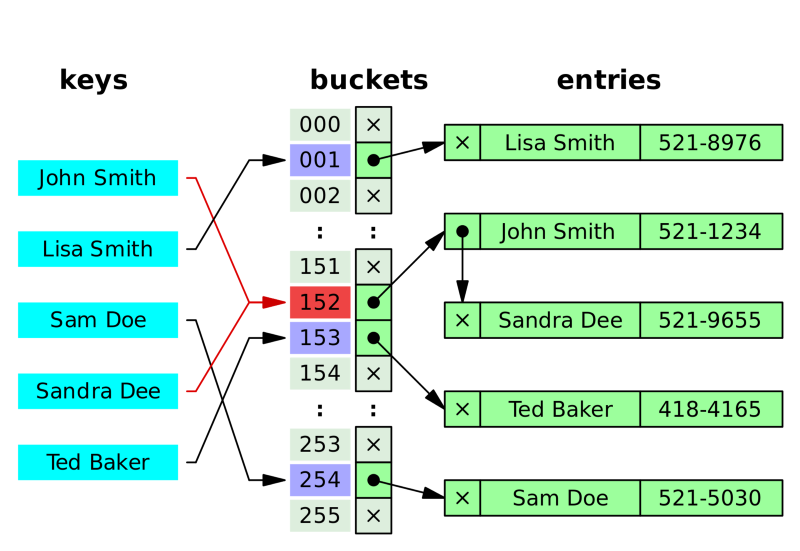
체이닝(Chainig)은 자료 저장 시, 저장소에서 충돌이 일어나면 해당 값을 기존 값과 연결시킴
Sandra를 저장할 때 충돌 발생 - 기존에 있던 John에 연결(연결 리스트 자료구조 이용) - 기존의 자료 다음에 위치시키는 것
- 장점
- 한정된 저장소의 효율적 사용
- 해시 함수를 선택하는 중요성이 상대적으로 적음
- 상대적으로 적은 메모리 사용 = 미리 공간을 확보할 필요 X - 단점
- 한 해시에 자료들이 계속해 연결되면 검색 효율 낮아짐
- 외부 저장 공간 사용
- 외부 저장 공간 작업을 추가로 해야 함
Chainig 시간복잡도
해시 테이블의 저장소의 길이를 n, 키의 수를 m이라고 가정
평균적으로 저장소에서 1개의 hash당 (m/n)개의 키 저장, 이를 α로 가정
m/n = α(1개 hash당 평균적으로 α개의 키가 들어있다.)
Insertion
충돌이 일어났을 때, 해당 해시가 가진 연결리스트의 헤드에 자료를 저장: O(1)
해시를 산출하고 저장하면서 기존 값을 연결하기만 하면 되기 때문
Tail에 저장할 경우, O(α)
모든 연결리스트를 지나서 끝에 접근해야 하기 때문
최악의 경우, O(n)
= 한 개의 해시에 모든 자료가 연결되어 있을 수 있기 때문
Deletion & Search
삭제와 검색은 시간복잡도 측면에서 비슷함
산출된 해시의 연결리스트 차례로 살펴보아야 해서 O(α)
최악의 경우, O(n)
= 한 개의 해시에 모든 자료가 연결되어 있을 수 있기 때문
2. Open Addressing(개방주소법)
비어있는 해시를 찾아 데이터를 저장하는 방법
1개의 해시와 1개의 값이 매칭되어 있는 형태 유지 가능
위의 그림에서 Ted의 해시도 Sandra가 저장되어 있어 그 다음 해시에 Ted를 저장함
비어있는 해시를 찾는 과정이 일정한 규칙을 따라가 동일하게 진행되어야 함
규칙에 따라 3가지로 구분 가능
- 선형 탐색(Linear Probing): 다음 해시나 n개를 건너뛰어 비어있는 해시에 데이터 저장
- 제곱 탐색(Quadratic Probing): 충돌이 일어난 해시의 제곱을 한 해시에 데이터 저장
- 이중 해시(Double Hashing): 다른 해시 함수를 한 번 더 적용한 해시에 데이터 저장
Open Addressing의 장단점
- 장점
- 다른 저장공간 없이 해시테이블 내에서 데이터 저장/처리 가능
- 또 다른 저장공간에서의 추가적 작업 X - 단점
- 해시 함수의 성능에 전체 테이블의 성능이 결정됨
- 데이터의 길이 늘어나면 그에 해당하는 저장소 마련 필요
해시 테이블의 저장소 길이를 n, 키의 수를 m이라고 가정
평균적으로 저장소에서 1개의 hash당 (m/n)개의 키 저장, 이를 α로 가정
m/n = α (α <= 1)
Insertion & Deletion & Search
삽입, 삭제, 검색 모두 대상이 되는 해시를 찾아가는 과정에 따라 시간복잡도 계산
해시 함수를 통해 얻은 해시가 비어있지 않으면 다음 저장소를 찾아야 함
O(1) ~ O(n)
Open Addressing에서는 빈 저장소를 확보하는 것이 중요
Map
- Object와 비교됨
- key-value로 이루어진 해시 테이블
get(),set()- key는 고유값, 단 1개만 존재
- key 자료형:
number,string,function,object,NaN
Map의 함수들
value 설정 :set()
value 얻기 :get()
value 찾기 :has()
value 삭제 :delete()
value 존재유무 :size
let map = new Map();
let num = 0;
let str = 'tomato';
let obj = {a: 1};
let func = () => {
console.log('func');
};
---
map.set(num, 2);
map.set(str, 1);
map.set(obj, 2);
map.set(func, 3);
map.set(num, 4); //덮어쓰기 가능
console.log(map);
---
map.get(str);
map.get(obj);
map.get('none');
map.get({a: 1});
---
map.has(str);
map.has(obj);
map.has('none');
---
map.delete(str);
map.delete('none');
---
map.size
map.lengthhash 탐색 :for-of 문
//key, value 쌍으로 출력 for (let [key, value] of map) { console.log(key + ' = ' + value) } //key만 출력 for (let key of map.keys()) { console.log(key) } //value만 출력 for (let value of map.values()) { console.log(value) }
참고자료
'CS' 카테고리의 다른 글
| RESTful API (0) | 2024.08.17 |
|---|---|
| [혼자 공부하는 컴퓨터 구조+운영체제]02 (0) | 2024.08.15 |
| [혼자 공부하는 컴퓨터 구조+운영체제]01 (0) | 2024.08.15 |